媒体別広告アルゴリズムを数式で理解!MMMで「全体最適」へ統合する考え方とは?

媒体別広告アルゴリズムを数式で理解!MMMで「全体最適」へ統合する考え方とは?

この記事は広告運用担当者やマーケティング責任者、データ分析に関心のある方を対象にしています。 媒体ごとに異なる広告アルゴリズムの基本構造を、数式で整理しながら理解し、MMMで全体最適に統合する考え方と実務の進め方を解説します。 個別最適に陥りがちな予算配分や指標のズレを防ぎ、短期と長期のバランスを取るための設計と検証の筋道も整理します。
広告アルゴリズムを掴む

広告アルゴリズムとは、どのユーザーに、どの広告を、どのタイミングで、いくらで出すかを決める計算と学習の仕組みです。 媒体ごとに入力データや最適化目標は違いますが、根っこは共通しています。
たとえば、検索は「今すぐ欲しい」層が多く、CPAが低く見えやすい一方で、動画やSNSは需要形成の要素が強く、短期のCPAだけで評価すると弱く見えます。 この状態で短期指標だけに寄せると、数週間〜数か月後に全体が落ちる(未来の検索需要が細る)ことがあります。 つまりズレは「媒体の計算式の違い」だけでなく、「役割の違い」からも起きます。
- 確率を予測する
- 予測に基づき期待値を最大化する
- 予算や配信制約の中で最適化する
配分判断を安定させるには、意思決定の“物差し”を先に決めるのが重要です。 例として、短期は獲得(注文数・粗利)、長期は需要(指名検索・再訪・LTV)というように、見たい成果を二段で分けます。 媒体ごとに担当KPIがバラバラな組織ほど、合意形成のための共通KPIが必要になります。
たとえば「短期の獲得」と「長期の需要形成」を同じCPAで見てしまうと、上流の投資が常に不利になります。 そのため、まずは次のように役割と見る指標をテーブルで固定しておくと、媒体ごとの数字が揺れても配分判断がブレにくくなります。
最適化の目的を知る
まず大事なのは、媒体が何を最大化しているかです。
売上だけで揃えると、値引きや粗利率の違いで判断がブレることがあります。 可能なら「粗利」や「貢献利益」に寄せ、少なくとも売上×粗利率のように一段補正した軸にすると、配分の一貫性が上がります。 また、計測欠損がある前提で過度に断定しない(幅で意思決定する)運用ルールもセットにします。 検索広告は獲得に直結しやすい一方、SNSや動画は反応や視聴の質が評価に強く効くことがあります。 運用側のKPIが、媒体の最適化方向とズレると、「数字は良いのに売上が伸びない」が起きやすくなります。
入札と配信の流れを追う
相互作用があるとき、媒体別レポートだけでは「どちらが効いたか」を切り分けにくくなります。 だからこそ、短期はテストで因果を押さえ、全体はMMMで“寄与の形”を推定して整合を取りに行く、という役割分担が有効です。 現場では、動画→指名検索→検索広告の獲得、のような“導線”を仮説として明文化しておくと、施策の評価がぶれにくくなります。
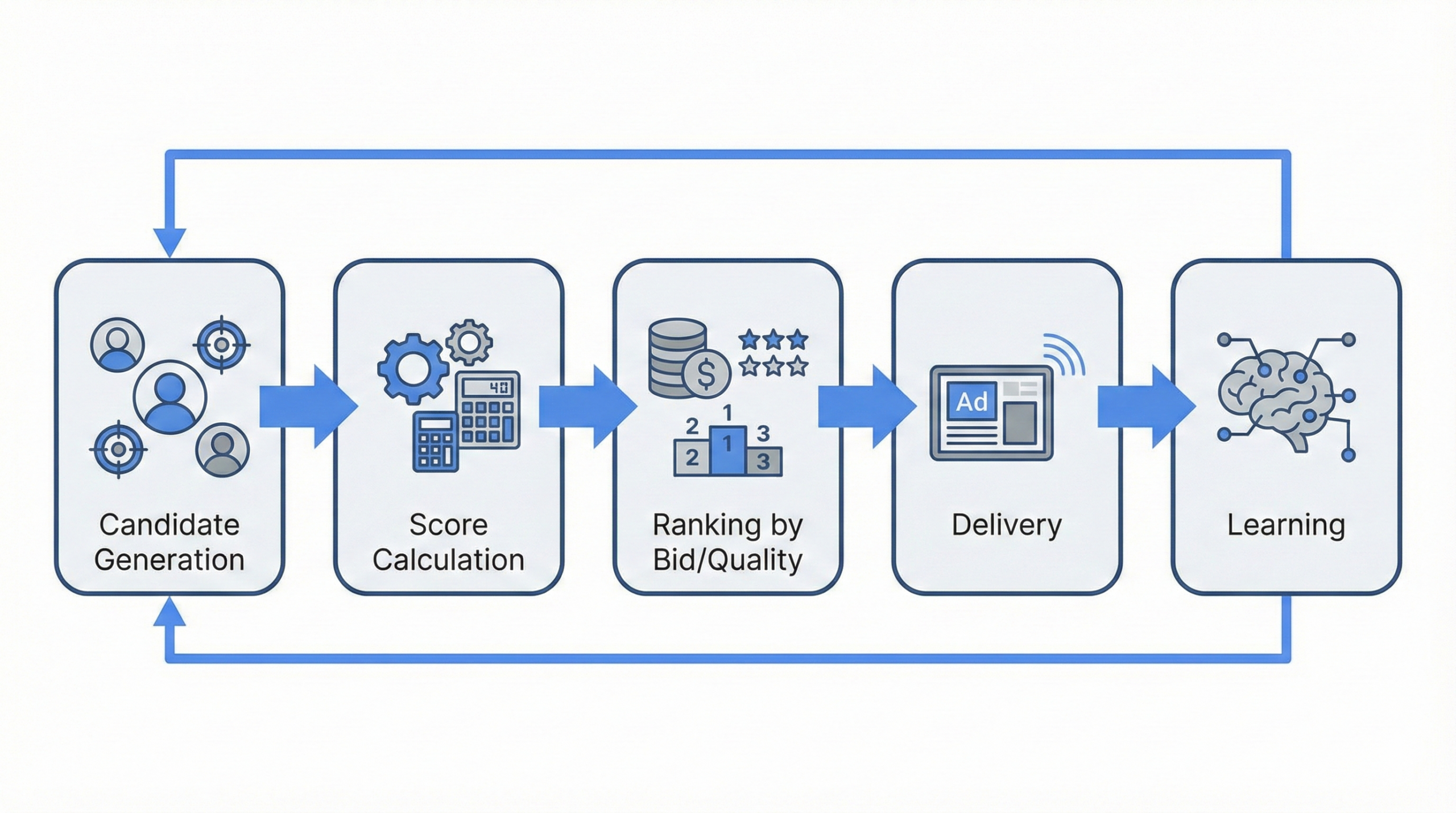
多くの媒体は、ざっくり次の流れです。
短期KPIだけに寄せると、クリエイティブが刈り取り寄りになり、将来の母集団が縮むことがあります。 逆に長期KPIだけに寄せると、短期のキャッシュ回収が遅れ、投資が続かなくなります。 短期と長期の比率(どれくらいを将来に投資するか)を意思決定として持っておくと、媒体別最適化が噛み合いやすくなります。
- 配信候補を作る
- 候補ごとにスコアを計算する
- 入札額とスコアで順位づけして配信する
- 実績を学習して次の配信を更新する
媒体側の管理画面のコンバージョンは、計測モデルや重複排除の方法が異なり、単純加算してはいけません。 また、計測制約が強い媒体ほど「見えない成果」が増えるため、見える指標だけで過小評価しやすくなります。 限界を前提にしつつ、媒体の短期指標・自社データ・テスト・MMMの複線で整合を取るのが実務的です。 このときスコアは、クリックや購入などの確率予測と、広告の品質評価を組み合わせて作られます。
ポイントは「媒体の管理画面の数字を正とする」ことではなく、「自社の目的変数(売上・粗利など)に対して、どの投入がどれだけ説明力を持つか」を推定することです。 媒体別最適化は各媒体の内部では賢いですが、全体最適の意思決定は“共通の目的変数”に戻して考える必要があります。 MMMはそのための“統合のものさし”として機能します。
数式で共通構造を見る
共通構造は期待値(確率×価値)で書けます。
形式的には、予算制約付きで予測成果を最大化する問題です。 ただし、現場で大事なのは「最適解一点」よりも「意思決定できる範囲」で比較することです。 実務では「推定値には不確実性がある」前提で、最適解一点を採用するよりも、許容レンジ(例:各媒体±10%)で複数案を比較する方が失敗しにくいです。
ここで x は状況、P(action|x) は行動確率、V はその価値です(確率×価値)。
媒体ごとの差は「何をactionと定義するか」「価値をどう置くか」「品質や制約をどう足すか」に集約できます。 たとえば同じ「購入」でも、定期購入か単発か、粗利率が高いか低いかで V(action) は大きく変わります。 また、同じ入札でも品質(関連性・体験・広告評価)や配信制約(学習量・配信面・上限)で結果が変わるため、入札だけを見ても全体は整理できません。
また、確率予測そのものは(モデルは何であれ)「状況xから確率を出す」という骨格で捉えるのが安全です。 実際の媒体はもっと複雑な特徴量やモデルを使いますが、運用の理解としては“確率×価値”を押さえれば十分に戦えます。
以下は公開情報に沿う範囲の簡易モデルです(実装詳細は非公開)。
Google広告を数式で追う

Google広告はオークションで広告枠を配分しつつ、学習で入札を自動化します。 検索は獲得に寄りやすい一方、品質の影響も大きく、入札だけで勝てるわけではありません。
期待値で入札を決める
自動入札の直感は次です。
入札は「CVが起きそうか」と「起きたときの価値」に応じて強くする、という理解で十分です。 たとえば価値を「CV=1件」と置くなら value=1、購入金額や粗利を置くなら value=購入価値 のように変わります。
目標CPA(tCPA)は「平均CPAが目標以下になるように配信を調整する」運用、目標ROAS(tROAS)は「平均ROASが目標以上になるように価値側へ寄せる」運用です。 数式で厳密化することもできますが、運用上は“目標を動かす=配信分布が変わる”ことを理解しておく方が効きます。
オークションと品質で配信が決まる
検索枠の配分は、入札だけではなく品質も加味されます。 Ad Rankは複数要素で決まりますが、実務の理解としては次の“簡易式”(品質Qが効く)が扱いやすいです。
Q(x) はオークション時の品質評価(推定CTR、関連性、LP体験などをまとめた概念)です。 この品質が低いと、同じ入札でも勝ちにくいうえに、勝てても効率が悪化しやすい点が重要です。
tCPAとtROASを調整する
tCPAやtROASを急に動かすと配信が大きく変わり、短期の数字もぶれます。 段階的に調整し、学習が落ち着くまでの観測期間を取り、同時に大きな変更を重ねないのが基本です。
Meta広告を数式で追う
Metaもオークションが基本で、Total ValueはBid・推定行動確率・広告品質の組み合わせだと説明されています。簡易モデルは次です。
p̂(action|x) は推定行動確率、q(x) は広告品質(フィードバックや低品質属性など)をまとめた項です。 重要なのは、bidだけ高くても p̂ や q が低いと勝ちにくい(=最適化はクリエイティブと計測も含む)という点です。
“価値最適化”は、イベント定義と計測の精度が悪いと学習がブレやすい領域です。 まずは購入に近いイベントに寄せ、データが安定してから価値側へ広げるのが安全です。
反応確率で配信が変わる
Metaは目的に応じて、購入や登録などの確率を学習し、確率が高いところに配信が寄ります。 運用側は、イベント定義と計測の一貫性を揃えることが最重要です。
重要シグナルを絞って使う
ノイズの多いイベントを増やすと学習が散ります。 最終成果に近いイベントを軸にし、必要ならキャンペーンを分けて役割分担すると整理しやすくなります。
目的に合わせて評価を変える
認知と獲得では、評価軸も必要データも変わります。 目的を混ぜると学習がぶれやすいので、目的ごとに設計を分けるのが安全です。
YouTube広告を数式で追う
動画は視聴の質が効きやすく、初動の反応が配信量に影響しやすいのが特徴です。 獲得を狙う場合でも、視聴が続かない広告は配信が伸びにくくなります。
視聴の質で配信が変わる
視聴率や視聴時間は、動画の価値を作る重要な入力になります。 同じ予算でも、冒頭数秒の設計で結果が大きく変わります。
視聴価値(見られるか、見続けられるか)が高いほど、配信が伸びやすく、結果として獲得にも波及しやすいのが動画の特徴です。 運用では、視聴指標(冒頭離脱、視聴維持、平均視聴)と獲得指標を分けて観測し、どこで落ちているかを切り分けます。
特に「冒頭で離脱する」のか「最後まで見られない」のかで打ち手が変わります。 尺や構成を変える前に、どの指標を改善すべきかを決めると、改善が速くなります。
ブランドと獲得を分けて運用する
ブランド目的と獲得目的は評価軸が違うため、同じ箱で最適化しない方が安定します。 目的を分けることで、学習の方向性が揃い、改善もしやすくなります。
X広告を数式で理解する
Xも配信はオークションが基本で、反応の確率予測が効きます。 拡散の二次効果はゼロではありませんが、運用判断ではまず一次の反応を安定して取りに行う方が堅実です。
拡散と反応で配信が変わる
反応が出る広告は配信が伸び、反応が弱いと伸びません。 そのため、訴求・構図・文言の改善で一次の反応を安定させることが、最短で効く改善になりやすいです。 拡散の二次効果はゼロではありませんが、まずは一次反応を“再現性のある形”で作れる状態に寄せる方が堅実です。
興味と属性を使い分ける
母集団を確保したいときは興味で広げ、最後は属性で絞るなど、段階的に設計すると学習を壊しにくいです。
媒体別最適が噛み合わない
媒体ごとの最適化は、その媒体内では合理的でも、全体ではズレを生みます。
媒体内KPIがズレやすい
クリック単価や反応率は、媒体ごとに文脈が違います。 単純比較すると、正しい配分ができないことがあります。
たとえばSNSの「反応」は獲得に直結しないことがあり、検索の「クリック」はすでに需要がある層に偏りやすいです。 さらに、計測窓(クリック後/表示後の期間)や重複排除のロジックが違うと、同じCVでも意味が変わります。 だからこそ、「媒体内の最適化KPI」と「全体で比較するKPI」を分けて設計します。
媒体別に「短期で見える指標」と「全体で比較する指標」をざっくり整理すると、次のようになります。
予算配分が誤りやすい
短期のCPAだけで寄せると、長期で効く投資が削られがちです。 短期と長期を分けて評価しないと、全体最適は作れません。
加えて、媒体ごとに「遅れて効く度合い」や「飽和の速さ」が違うため、同じ期間の数字だけで判断すると過大/過小評価が起きます。 実務では、配分を一気に動かすよりも、変更幅を決めて段階的に動かし、観測期間を取ってから次の一手を決める方が安定します。
比較軸を統一して見る
比較は共通の価値軸に揃えます。 直感としては「期待売上」や「貢献利益」に寄せるのが現場で扱いやすいです。
具体的には、媒体別に「売上」だけでなく粗利率・返品率・LTVの差を反映し、最終的に同じ土俵(例:週次の貢献利益)へ揃えます。 この“揃え方”を決めておくと、媒体側の指標が揺れても、配分判断の芯がブレにくくなります。
統合の必要を理解する
全体最適が必要なのは、媒体間の相互作用や重複接触があるからです。
媒体間の相互作用を見る
動画が検索の指名を増やす、SNSが検索のCVRを押し上げるなど、先行効果が起きます。 個別媒体の最適化だけでは、この影響を拾えません。
相互作用があると、最後にクリックされた媒体だけが“勝って見える”一方で、先行媒体は過小評価されます。 この歪みを放置すると、短期で強い媒体に寄せ続け、やがて全体が伸びにくくなることがあります。
短期と長期を分けて考える
短期は獲得、長期は需要の形成です。 同じKPIで両方を追うと判断が歪みやすいので、評価軸を分けます。
現場では「短期=獲得効率」「長期=需要の母集団」を同時に見て、短期の上振れ/下振れで長期投資をゼロにしないガードレールを作ります。 このガードレールがあると、媒体別にKPIが違っても、全体の意思決定は一貫します。
計測の限界を押さえる
アトリビューションの偏りや欠損は避けられません。 見えている数字だけで断定せず、統合推定で補完する発想が必要です。
特にiOS計測制約やCookie制限の影響で、媒体の管理画面CVは“増えたり減ったり”します。 その揺れを前提に、テストで因果を押さえつつ、MMMで配分の整合を取ると判断が安定します。
MMMで統合して推定する
MMMは、複数媒体の投入が成果に与える寄与を、同じ土俵で統計モデルとして推定します。 基本の形は次のように書けます。
y_t は売上などの成果、x_{i,t} は媒体ごとの投入、s(t) は季節性など、g_i は効果の形を表します。 「媒体の投入が、どのタイミングで、どの形で効いているか」を同じ土俵で推定するのがMMMの強みです。
ここで重要なのは、媒体の効果だけでなく「売上を動かす他の要因」も同じ時間軸で入れることです。 価格改定、セール、在庫、競合、季節イベントなどを入れずに広告だけで説明しようとすると、広告効果を過大評価しやすくなります。 逆に、必要な要因を足しすぎて説明変数が増えすぎると不安定になるので、まずは“強い外部要因”から優先して入れるのが実務的です。
遅延と飽和を入れて現実に寄せる
実務では、遅延と飽和を入れないと過大評価しやすくなります。 代表的にはアドストックと飽和の関数を使います。
この式は「広告の効果が当週だけで消えず、翌週以降にも残る」ことを表現します。 実務では媒体によって遅延の強さが違うので、同じλを固定で当てはめず、推定でフィットさせる(または候補を比較する)方が安全です。
さらに、広告は投入を増やすほど効き続けるわけではなく、どこかで逓減します。 この飽和(diminishing returns)を入れる代表例がHill関数です。
k は半飽和点、n は立ち上がりの鋭さ(形状)です。 投入を増やしても効きが逓減する(一定以上は伸びにくい)という現実を、モデルに織り込むために使います。 MMMでは、媒体投入をアドストックして飽和を通してから目的変数に効かせる形が定番です。 この2つ(遅延・飽和)を入れることで、媒体Aは“効き始めが遅いが長く残る”、媒体Bは“即効だがすぐ飽和する”のような差を同じ枠組みで比較できます。
予算配分へ落とし込む
推定した寄与を使い、予算制約の中で配分を決めます。 ここで重要なのは、単一の数字で確定させず、シナリオで幅を見て意思決定することです。
形式的には、予算制約付きで予測成果を最大化する問題です。 ただし、現場で大事なのは「最適解一点」よりも「意思決定できる範囲」で比較することです。
実務では「推定値には不確実性がある」前提で、最適解一点を採用するよりも、許容レンジ(例:各媒体±10%)で複数案を比較する方が失敗しにくいです。
配分の検討では「現状配分」「守り(短期寄せ)」「攻め(需要形成寄せ)」のように、少なくとも3案を並べると議論が進みます。 このとき、媒体別の上限(在庫・配信面・学習量)や、増やしたときに効率が落ちる速度(飽和)を合わせて見ます。 最後は、モデルの最適解ではなく「運用として回せるルール」に落とし込みます(例:変更幅、観測期間、例外条件)。
実務で回して改善する
MMMは一回作って終わりではなく、運用で回す仕組みが重要です。
必要データを揃えて始める
MMMは“あるデータだけで魔法のように答えが出る”ものではありません。 まずは投入(コスト)と成果(売上など)の定義を揃え、粒度(週次/日次)を決めて、継続的に取れる形にします。 加えて、価格改定や販促などの社内要因も同じ時間軸に載せると推定が安定します。
運用現場で詰まりやすいのは、媒体の費用と成果の「締め時間」「通貨」「計上タイミング」がズレることです。 週次に揃えるなら、週の区切り(何曜日締めか)を明示し、集計ルールを固定してからモデル化に入ると、後戻りが減ります。 また、広告費は税抜/税込、値引きは売上から控除するかなど、財務/CRM側の定義に合わせておくと、後段の意思決定がしやすくなります。
- 媒体別の費用
- 媒体別の配信指標と成果
- 価格や販促などの社内要因
- 季節性やイベントなどの外部要因
上の項目は、チームで認識がズレやすいので、最初に「誰が」「どの粒度で」「どの定義で」持つかを表にして固定します。
粒度と定義を揃え、欠損や遅延を把握した上で使います。
欠損がある場合は「欠損をゼロ扱いしてよいのか」「そもそも計測不能なのか」を分けます。 媒体の仕様変更で系列の意味が変わることもあるので、仕様変更のログ(いつ何が変わったか)を一緒に残しておくと解析が安定します。
テストと併用して検証する
MMMは全体の配分判断に強い一方、短期の因果を“確定”させるのは不得意です。 そこで、短期はテスト(AB、地域差分、配信オンオフ)で押さえ、長期や横断配分はMMMで見る、という分担が現実的です。 両者の結果が矛盾したら、変数の定義や期間、外部要因の入れ方を見直します。
テストは「その条件で本当に増分があったか」を押さえるのに強く、MMMは「他媒体も含めた全体の配分として整合するか」を見るのに強い、という役割分担です。 片方だけで完結させず、矛盾が出たときに“どこを疑うか”の優先順位(計測→期間→定義→外部要因)を決めておくと回しやすいです。
最初から完璧に当てようとせず、「ズレた理由を説明できるか」を改善の軸にすると回しやすいです。
変化に備えて再推定する
媒体の配信仕様、計測の制約、市場環境は定期的に変わります。 一度作ったモデルを固定すると、いつの間にか“過去に最適化された判断”になりがちです。 定期再推定と、前提が崩れていないかを見る監視指標をセットにします。
監視は「予測の外れ(残差)が増えた」「特定媒体の寄与が急に変わった」「季節性がズレた」など、モデルの前提が崩れたサインを早く拾うためです。 再推定の頻度(例:四半期ごと)と、緊急で見直す条件(仕様変更、大型施策、計測仕様の変更)を決めておくと運用が安定します。
媒体仕様や市場は変わります。 定期的に再推定し、変化を検知する指標も用意しておくと、運用が安定します。
まとめ
媒体別のアルゴリズムは違って見えても、確率予測と期待値最適化という共通構造があります。 ただし媒体内の最適化を積み上げても、全体最適にはなりません。 MMMで統合して推定し、短期と長期を分けながら、説明可能な予算配分と運用方針に落とし込んでいきましょう。
Author
nakasi0210